At ZeroDay.Cloud 2025, Team "Bugz Bunnies" discovered a 20-year-old encoding bug in PostgreSQL's pgcrypto extension.

As part of ZeroDay.Cloud 2025, researchers Moritz Sanft and Paul Gerste uncovered a critical zero-day vulnerability in the PostgreSQL database server, enabling remote code execution (RCE). The underlying bugs have been disclosed in collaboration with the Wiz Research Team, and the PostgreSQL maintainers have fixed them since.
Mitigations
- Update PostgreSQL to 18.2, 17.8, 16.12, 15.16, or 14.21 as soon as possible.
- Ensure that only trusted clients can send queries to Postgres instances.
- If exposed applications interact with Postgres instances, vet them carefully to minimize the possibility of SQL injections, which often provide enough surface to exploit this vulnerability.
The vulnerability
The bug is located in 20-year-old code of the pgcrypto extension, which is bundled with the default Postgres distribution, and "trusted". This means that the extension can be enabled by any authenticated user, including non-superusers, via CREATE EXTENSION pgcrypto.
A function in the pgcrypto extension violated a critical security assumption in Postgres: that all strings handled in the database server conform to the "database encoding". This allowed smuggling tainted strings into the database server and having them processed in other functions which rely on the database encoding assumption being held. Consequently, when the assumption was broken, these functions could be exploited to read and write arbitrary memory, allowing for remote code execution.
Database encodings
To a human, strings are essentially sequences of characters. However, software doesn't have this notion of character sequences, but operates on raw bytes in memory. Therefore, it needs to decide how to serialize them to bytes to store them in memory. This is where encodings come into play, which specify how to do this serialization. The most popular encoding is ASCII, which saves characters as single-byte values. Other decodings, such as UTF-8, use a dynamic number of bytes for encoding a single character, making their handling more delicate. In the context of databases (Postgres, specifically), these encodings define how character strings are stored and processed within Postgres.
A critical, long-held assumption in the Postgres core is that all strings handled by the database server conform to the configured database encoding. It's such a fundamental thing that changing your database's encoding requires recreating it from scratch and then importing all the data again. Functions in Postgres rely on this assumption to correctly and safely handle string operations. The violation of this assumption, by allowing malformed, non-compliant strings to be introduced, is the key to triggering the memory corruption vulnerability.
Postgres extensions
Postgres extensions are modules of code that add functionality to the database. They can be installed by users to provide new data types, functions, or features. The vulnerability is located in the pgcrypto extension which can be used to perform cryptographic operations on database contents, such as creating signatures or hashes, or decrypting content dynamically.
The pgcrypto extension is particularly relevant because it is marked as "trusted". Trusted extensions can be installed and enabled by any authenticated user, even a non-superuser, using the CREATE EXTENSION pgcrypto; command. This low bar for enabling the vulnerable code path significantly broadens the attack surface for exploitation of this vulnerability.
A faulty function
In pgcrypto, the pgp_sym_decrypt function takes a msg (the ciphertext) and a psw (the key), and decrypts the PGP-encrypted message with the given symmetric key. Its return value is a character string of type text, which is the Postgres type for an arbitrary-length string.
PGP uses a special format for encoding the data it uses. For example, a PGP-encrypted message could look like this:
-----BEGIN PGP MESSAGE-----
Version: 2.6.2
hIwD1vwet/TdJfEBBACdcCPkNI3k…
The "-----BEGIN PGP MESSAGE-----" sequence marks the start of the message. The next part is the message header. Version: 2.6.2 is the only header field and indicates the version of the PGP standard used to create the message. The raw message bytes follow, encoded as Base64. These bytes are not the actual ciphertext, they contain another layer of structure as documented in the RFC.
In the Postgres PGP implementation, a message can be encoded in ASCII or Unicode. A Unicode-encoded message is indicated in the message header by setting the unicode-mode header field, which is unique to Postgres and not present in the original OpenPGP standard. When the Unicode flag is set in the PGP message, the decrypted message is converted from UTF-8 into the database encoding, which includes checks on whether the decrypted message results in valid UTF-8 characters.
However, when the Unicode flag is not set, no validation takes place, allowing invalid characters to be smuggled into the database. To achieve this, an attacker simply encrypts invalid UTF-8 with a chosen key outside of Postgres, e.g. with the gpg CLI, and then decrypts it with the pgp_sym_decrypt function in Postgres.
Broken assumptions
Internally, Postgres uses the pg_mblen function to calculate multi-byte character length for the multi-byte encodings it supports. For UTF-8, pg_mblen redirects to pg_utf_mblen. This function demonstrates Postgres's assumption that all strings in the database conform to the database encoding really well.
int
pg_utf_mblen(const unsigned char *s)
{
int len;
if ((*s & 0x80) == 0)
len = 1;
else if ((*s & 0xe0) == 0xc0)
len = 2;
else if ((*s & 0xf0) == 0xe0)
len = 3;
else if ((*s & 0xf8) == 0xf0)
len = 4;
#ifdef NOT_USED
else if ((*s & 0xfc) == 0xf8)
len = 5;
else if ((*s & 0xfe) == 0xfc)
len = 6;
#endif
else
len = 1;
return len;
}
To determine the length of a UTF-8-encoded character, the function only looks at the first byte of the byte sequence representing the character. Under the assumption of valid UTF-8, this implementation is perfectly fine, since the first byte in an UTF-8-encoded character denotes how many bytes will follow. To understand the rationale, let's examine how UTF-8 works.
UTF-8 is ASCII-compatible, which means that the characters in the ASCII range [0, 127] are also encoded as the same, single-byte characters. When encoding characters with higher code points than 127, UTF-8 encodes the length of the sequence into the upper bits of the first byte and then appends the rest. There are four valid starting byte patterns in UTF-8:
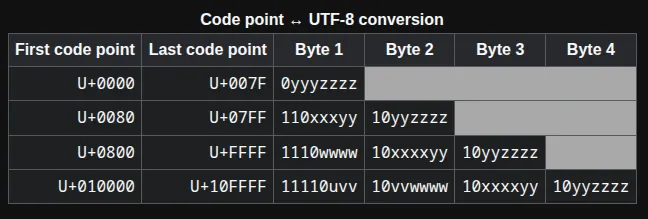
Source: Wikipedia
As we can see, a starting byte that has the four most-significant bits (MSBs) set to 1, followed by a 0, marks the start of a 4-byte sequence. Each continuing byte has to have the MSBs 10 to be considered valid.
If we compare that with the pg_utf_mblen function, we can see it does not validate the continuing bytes. This missing validation would be acceptable if strings always are valid UTF-8. In many places, the database enforces this, but with the pgp_sym_decrypt bug described above, this assumption is broken, converting otherwise-valid functions such as pg_mblen into the attacker's first foot in the door.
Exploitation
A faulty length function is a good first step on our journey to code execution, but there's still a long way to go. We started to look for uses of the pg_mblen function to see if we can corrupt some memory with it.
Leaking heap data
The first interesting use we found is within the reverse function, which, as the name indicates, reverses text. It does so by creating a same-size buffer as the source string and then copies the contents in reverse order:
const char *p = VARDATA_ANY(str);
int len = VARSIZE_ANY_EXHDR(str);
const char *endp = p + len;
// [...]
result = palloc(len + VARHDRSZ);
dst = (char *) VARDATA(result) + len;
// [...]
while (p < endp)
{
int sz;
sz = pg_mblen(p);
dst -= sz;
memcpy(dst, p, sz);
p += sz;
}
The dst pointer starts at the end of the target buffer and is decremented by the length of the character that is about to be copied. In most cases this should work as expected, but this behavior breaks if a dirty string ends with a byte that looks like the starting byte of a 4-byte UTF-8 sequence. In this case, the last iteration will have a dst equivalent to index 1 (only one byte left in the target buffer), but sz is 4 since pg_mblen thinks there is a 4-byte character. This will decrement dst to an equivalent of index -3, causing the memcpy to overwrite the 3 bytes before the target buffer.
To understand the impact of this new primitive, let's examine some internal structs. Postgres saves strings along with a length header, which is placed right before the actual contents of the string in memory. The varlena struct has a vl_len_ field (4 bytes) followed by vl_dat[] (the string content). The vl_len_ field holds extra flags in its 2 least-significant bits — the actual length includes the header length and is shifted up by 2 to make room for the flags.
Since reverse allows us to overwrite up to 3 bytes before the target buffer (vl_dat), we can corrupt the 3 most-significant bytes of the string length. This can either be used to corrupt a very long string to make it appear smaller than it actually is, or corrupt a small string and make it appear larger than it actually is. The latter is of course more interesting, as the corrupted string will overlap with other data that is located after it on the heap. If we use such a corrupted string, we might read or modify that data.
At first, we thought that this was it and we can now read and write out-of-bounds on the heap, bringing us much closer to our final goal of executing code. However, we quickly noticed a problem: most objects that hold raw data (strings, byte arrays, etc.) are immutable! This means we can still use a corrupted string to read OOB, but when trying to modify such a string, a copy is created and modified instead.
To finish our OOB read primitive, we still needed a way to retrieve the "whole" corrupted string (based on its new length). However, many places use strlen when determining how many bytes to copy when dealing with strings and the reverse function correctly places a null byte at the correct place. We therefore needed a function that trusts varlena's length field instead of computing the length itself, and that would not choke on null bytes or invalid UTF-8 byte sequences that will likely appear in raw heap memory.
Conveniently, the pgcrypto extension also offers the pgp_sym_encrypt function, which fulfills these exact requirements. By "encrypting" the corrupted string with a chosen key and decrypting it outside of Postgres, the out-of-bounds-read contents can be leaked from the database. This leaks several pointers from Postgres's memory and allows to defeat ASLR and PIE, by shaping the heap to contain pointers to the binary, libc, or the heap right after a corrupted string.
Writing out-of-bounds
To convert the size miscalculation in pg_mblen to a more helpful write primitive, we had to search for different uses of that function. One interesting candidate is the to_number function which is meant to decode a numeric string into a number type (integer, float, etc.) based on a given format string. For example, to_number('12,454.8-', '99G999D9S') (G for "Group separator", D for "Decimal point", and S for "Sign") returns the number -12454.8.
When parsing the format string, to_number calls parse_format under the hood which in turn uses pg_mblen to advance the string pointer to the next character:
while (*str)
{
// [...]
chlen = pg_mblen(str);
n->type = NODE_TYPE_CHAR;
memcpy(n->character, str, chlen);
n->character[chlen] = '\0';
n->key = NULL;
n->suffix = 0;
n++;
str += chlen;
}
If the format string (str) is a dirty string, the last byte may, again, indicate a multi-byte character, even though there is only one byte left in the string. Since the str pointer is incremented by the chlen returned from pg_mblen, the terminating null byte of the string is skipped by the parser! The parser might now continue to process the data on the heap that comes after the format string, which we can control by shaping the heap accordingly.
But the loop does not only read memory, it also performs writes: in each iteration, the n pointer is written to and then advanced. The buffer that n points to was allocated based on the format string length:
len = VARSIZE_ANY_EXHDR(str);
format = (FormatNode *) palloc((len + 1) * sizeof(FormatNode));
memset(Num, 0, sizeof *Num);
parse_format(format, str, NUM_keywords, NULL, NUM_index, NUM_FLAG, Num);
The format buffer that n points to has one FormatNode slot per format string byte (plus one extra). This is usually more than enough but falls apart when parse_format processes more data than is present in the string. Since this is exactly what happens when the parser skips the terminating null byte and continues on the heap contents after it, n will eventually grow outside the bounds of the allocated format buffer. Each subsequent use of n to write data will therefore write out-of-bounds on the heap.
Constructing an arbitrary write primitive
To turn a relative OOB write into a more powerful primitive, we looked for interesting data on the heap and found the AllocBlockData struct from the AllocSet allocator:
typedef struct AllocBlockData
{
AllocSet aset;
AllocBlock prev;
AllocBlock next;
char *freeptr;
char *endptr;
} AllocBlockData;
The freeptr holds the address of the next allocation, so by overwriting it we can control the return value of the next allocation and overlay it with arbitrary memory. However, our current OOB write primitive does not give us full control of the data that is written. By overlaying the FormatNode and AllocBlockData structs, we can see that the write operations mainly modify the lower 3 bytes of the freeptr. The second to last byte that is set to a null byte is essentially a no-op because the upper 16 bits of a pointer are zero anyway.
In most cases, this modification will make the freeptr point to memory that is ~16 MB before the block header itself. By repeating a lot of allocations, we can increase the freeptr again until it points to itself. When doing the next allocation and writing user-controlled data to it (e.g., by creating a byte array), we can overwrite the freeptr with an arbitrary address. We can then write to this address by creating another allocation with user-controlled content.
Executing code: a handy gadget
Since we can leak the binary's base address with our first reverse technique, and now have a write-what-where primitive, we are set up for success. All that is left is finding a nice thing to overwrite and either pivot to a ROP chain or, even easier, directly execute shell commands.
When searching for ways to do the latter, we found that each runtime-controllable Postgres setting can have a callback that is called when the setting is changed and receives the new setting value as the first argument. These settings live in a big struct in the binary's data section, which we know the address of! All that is left to do is finding a string setting we can change at runtime, overwriting its callback with a system-like function, and changing the setting to an OS command of our choice.
We settled on the search_path setting and overwrote its callback with the ExecuteRecoveryCommand function, which essentially calls libc's system function with the contents of the given Postgres text object as the command argument. With everything in place, we can execute arbitrary OS commands with a simple Postgres query:
set_config('search_path', 'id > /tmp/pwned')
Impact
Memory corruption vulnerabilities like this in PostgreSQL server core are quite rare, and the impact is significant. Any authenticated database client could use this vulnerability to achieve code execution on affected infrastructure — potentially moving laterally from there, as database servers are usually positioned in close proximity to the main client application for performance reasons. For clients like a web application, the risk is significantly higher, as attackers could use this vulnerability to escalate a simple SQL injection into a full-blown remote code execution. This attack surface could allow for remote, unauthenticated exploitation, making this vulnerability critical.
Remediation
Patch now
A patch was released across all major versions of PostgreSQL on Feb 12, 2026: PostgreSQL 18.2, 17.8, 16.12, 15.16, and 14.21.
Upgrade to the patched minor release for your major version. PostgreSQL minor upgrades are designed to be low-risk; staying on an older minor release carries more risk than upgrading.
Cloud managed PostgreSQL services may roll out patched engine versions on their own schedules. Check your provider's bulletin.
If you can't patch yet
Reduce exploitability and blast radius while you schedule patching:
- Tighten network access: ensure PostgreSQL is not directly internet-exposed; limit connectivity to known application subnets and trusted admin networks.
- Credential hygiene: rotate broadly-distributed database credentials (apps, CI/CD, secrets stores); prefer per-service identities and short-lived credentials.
How Wiz can help
Wiz customers can use the pre-built query and advisory in the Wiz Threat Center to surface vulnerable instances in their environment. Wiz also helps prioritize publicly exposed instances of PostgreSQL and identify any instances configured with weak authentication or allowing SQL injection.
Disclosure timeline
- Dec 11, 2025: Team "Bugz Bunnies" (Paul Gerste and Moritz Sanft) demonstrate the vulnerability on-stage at ZeroDay.Cloud 2025 in London.
- Dec 11, 2025: The vulnerability is disclosed to the PostgreSQL maintainers.
- Feb 12, 2026: The fix is released as part of PostgreSQL 18.2, 17.8, 16.12, 15.16, and 14.21.
- Feb 12, 2026: CVE-2026-2006 is assigned.
Conclusion
CVE-2026-2006, a 20-year-old RCE vulnerability in a core PostgreSQL component, highlights how decades-old memory corruption bugs can persist undetected in trusted extensions. This flaw is reachable by any authenticated user, meaning a very large attack surface, especially when combined with common issues like SQL injection.